

Brněnské vodárny a kanalizace (BVK) nám před časem nainstalovaly chytrý vodoměr, který denně odesílá stavy. To se hodí nejen, když chcete mít přehled o spotřebě, ale také pokud chcete předejít větším škodám při haváriích. Máme akumulační nádrž na dešťovou vodu, z které zavlažujeme zahradu. Pokud dešťovka dojde, může se automaticky dopouštět z řadu. Dopouštění vypíná plovák a už jsem slyšel o nejednom případu, kdy se dopouštění přestalo vypínat, voda přitékala nonstop z řadu a přepadem odcházela do kanalizace. A účet za vodu naskakoval.
Proto jsem začal přemýšlet nad tím, jak dostat hodnoty z vodoměru do Home Assistantu, kde bych si nastavil automatizaci, která by mě na jakoukoliv zvýšenou spotřebu upozornila. Samy vodárny mají vlastní výstražný systém, ale ten má podle všeho hodnoty alarmů nastavené vysoko, protože napuštění 30 kubíků do bazénu žádný alarm nespustilo, a u nás by nějaký problém značila už desetinová hodnota.
Slepé uličky
Poslední odečtenou hodnotu vodoměru si můžete přečíst po přihlášení do svého účtu na stránkách BVK, ale neposkytují ji v žádné jednoduše strojově čitelné podobě. Používají vodoměry SUEZ a pokud si chcete přečíst stav vodoměru, přesměrují vás na jejich portál. Našel jsem, že v některých zemích je dostupné API a integrace do HA. Když jsem se ale na API zeptal BVK, poslali mě do háje. Tudy cesta nevedla.
Další možností je přistoupit k vodoměru jako k hloupému a pořídit si zařízení, které dokáže odčítat ciferník vodoměru. Jedná se ale o řešení, které není moc spolehlivé, když se vodoměr nachází v prostoru s vysokou vlhkostí. Máme vodoměr venku v šachtě a běžně se na ciferníku nachází voda, která jakékoliv obrazové odčítání znemožňuje. Šachta je vlhká a není do ní dovedená elektřina. To vše takové řešení výrazně komplikuje. Ani tudy cesta nevedla.
Další možností je odchytávání radiového signálu. Ten je podle všeho odesílán v nelicencovaném pásmu 169 MHz na přijímač, který se typicky nachází do 3 km. Nicméně jak jsem se dozvěděl, chytré vodoměry SUEZ používají protokol Wize, který má šifrování AES-128. Každý vodoměr má unikátní šifrovací klíč, který mi jako zákazníkovi nevydají. Tudy cesta také nevedla.
Zbývala tedy cesta, do které se mi chtělo nejméně: scrapování webu BVK a odečítání stavu vodoměru z portálu SUEZ tímto způsobem.
Rozhodl jsem se také, že to pojmu jako experiment s AI. Doteď jsem AI používal na pomoc při programování u jednotlivostí, případně u jednorázových skriptů. Teď jsem si řekl, že si vyzkouším, jak si AI poradí s výstavbou celého projektu.
Jak se dostat ke stavu vodoměru
BVK přečtení stavu vodoměru opravdu nijak nezjednodušují. Na hlavních stránkách bvk.cz se musíte prokliknout na zákaznický portál, na kterém se musíte přihlásit:
Po přihlášení musíte kliknout na Má odběrná místa v nabídce:
Dostanete se na stránku se seznamem odběrných míst, kde musíte kliknout na to, které vás zajímá. Já mám aktivní pouze jedno:
Poté se dostanete na stránku vybraného odběrného místa, na níž se v pravém horním rohu nachází ikona Smart vodoměry. Pod ní se nachází odkaz, který vás přesměruje na portál SUEZ:
Teprve na portálu SUEZ se nachází stav vodoměru. A ještě vykreslený JavaScriptem tak, aby napodoboval skutečný vodoměr:
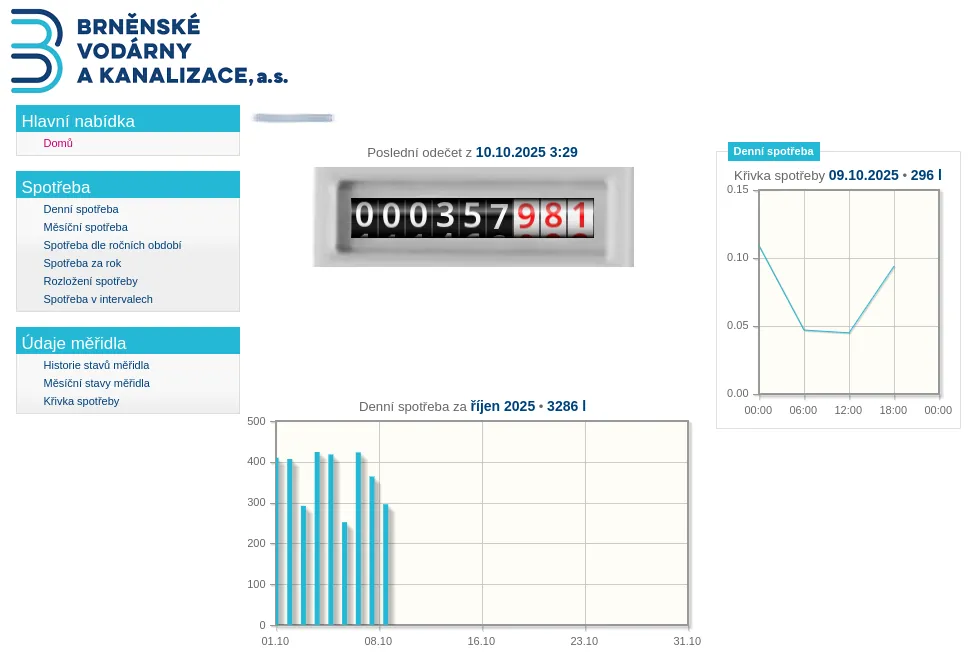
Přesměrování ze zákaznického portálu BVK na portál SUEZ probíhá přes odkaz s přiloženým autentikačním tokenem, což mi na chvíli dalo naději, že by token mohl být trvalý a mohl bych tak použít přímo odkaz a přeskočit všechny předchozí kroky. Jak jsem ale zjistil, token se obnovuje každý den a proklikání se obrazovkami zákaznického portálu BVK se tak nevyhnu.
Také jsem zkoušel, jestli by nebylo možné stav vodoměru vyscrapovat jednoduše textově např. pomocí curl. Pokud by si mohl stav odečítat přímo Home Assistant, celou věc by to výrazně zjednodušilo. HA provozuji za Home Assistant Green s HAOS a tam plnohodnotný prohlížeč rozumně nerozjedu. Nicméně s curlem jsem pohořel už na přihlášení, kdy jsem nemohl najít takovou konfiguraci, kdy by mě portály BVK a SUEZ detekovaly jako prohlížeč a pustily dál. Myslím, že podobně by pohořela i integrace Scrape v HA, která si poradí jen s jednoduchými stránkami.
Práce s AI
Nezbylo mi tedy nic jiného než rozjet scrapování na vlastním serveru, který pak bude stav vodoměru ve strojově čitelné podobě předávat HA. V tomto momentě jsem se poprvé obrátil na AI (konkrétně Claude), aby mi takové řešení navrhla. Součástí zadání bylo, že cílovým systémem má být Fedora Linux 42. AI vystavěla scraping na Playwright, aby následně zjistila, že to nemůže rozjet, protože jedinou platformou podporovanou Playwrightem je Ubuntu. Když jsem ji upozornil na to, že od začátku je součástí zadání, že má řešení fungovat na Fedora Linux 42, uznala chybu a začala scrapování přepisovat do Selenia.
Celý proces se vyznačoval hledáním cest a neustálým korigováním z mé strany. Ne, že by se AI nedokázalo (téměř) samo dobrat funkčního řešení, ale velmi často takové řešení nedávalo velký smysl, bylo neefektivní nebo i nebezpečné.
Úplně na začátku navrhlo dvě služby, kdy jedna bude dělat samotné scrapování, a druhá pak poskytovat hodnoty vodoměru přes REST API Home Assistantu. První službu ale navrhlo tak, že běžela a spotřebovávala systémové zdroje neustále, přičemž v zadání bylo, že má scrapování probíhat jen dvakrát denně. Až po mém návrhu ji předělalo na jednorázovou, která se pouští systemd timerem.
Podobně si AI počínalo při řešení předávání hodnoty mezi službami. Původně řešení vystavělo na protokolu MQTT a použití brokeru. Přitom to bylo naprosto zbytečné. Obě služby běžely na stejném stroji ve stejném jmenném prostoru, mohly prostě používat sdílený soubor. Lidský programátor přirozeně směřuje k jednodušším řešením, protože napsat složitá řešení vyžaduje čas, který je drahý. AI ale toto omezení nemá, dokáže i složité řešení napsat během chvilky. Jenže ono to není jen o času potřebném na danou implementaci, složitější řešení jsou náročnější na systémové zdroje, náchylnější k problémům a bezpečnostním chybám.
Občas si chtělo AI vypomoct docela prasáckým způsobem. Když si chtělo odkládat nějaké dočasné soubory do /tmp, ale nemohlo, protože proces neběžel pod rootem, přišlo s řešením „sudo chmod -R 777 /tmp“, které jsem mu zatrhl s tím, že to z bezpečnostního pohledu nebude určitě optimální, načež přišla typická odpověď „Výborná připomínka! Máte naprostou pravdu!“
A někdy to prostě nezvolilo bezpečné řešení. Hodnoty vodoměru to původně chtělo přes REST API poskytovat zcela bez šifrování a bez ověření. Ono má důvod, proč i vodárny odčítají stavy šifrovaně. Podle vývoje hodnot lze jednoduše určit, jestli je někdo doma nebo ne. Proto ani není dobrý nápad vystavovat odečtené hodnoty jen tak na Internetu. Až po mém zásahu se služba umístila za web proxy s HTTPS a začal se vyžadovat autentikační token.
Nicméně některé aspekty programování s AI se mi i líbily. Na jakoukoliv novou funkcionalitu si automaticky napíše test, který má hlavu a patu. Ručně by se mi testy v takovém rozsahu psát nechtělo, zvlášť u takového rychlého hobby projektu. Také se mi líbí výstupy do logů, které jsou dostatečně podrobné a hlavně srozumitelné. AI je píše primárně kvůli sobě, aby mohlo program lépe debuggovat, ale i já jako uživatel jsem díky tomu měl jasnou představu, co program aktuálně dělá a na čem se zasekl.
Příprava na zveřejnění
Na konci byl sice funkční kód, ale v takovém prototypovém stavu. Obsahoval artefakty ze slepých cest, které se v průběhu tvorby zahodily. AI samo od sebe nechtělo žádnou funkcionalitu odstraňovat, i když jsem ji odmítl, raději ji jen vypnulo. Anebo ji zapomnělo, když to nemělo žádný přímý vliv na funkčnost celého programu. Musel jsem explicitně požádat, aby ji odstranilo. A ani to nefungovalo vždy spolehlivě.
Když tedy došlo na poslední část cvičení – připravit projekt na zveřejnění jako open-source software, neobešel jsem se bez ručních zásahů. Nakonec jsem to dostal do stavu, kdy je to zveřejnitelné a může to posloužit i někomu jinému. Nicméně pokud by se mělo jednat o seriózní open-source projekt, musel bych jej verifikovat řádek po řádku a vyčistit opravdu důkladně, což už bych se dostával k takové časové dotaci, že by se možná vyplatilo si to napsat ručně (kdybych měl zkušenosti se Seleniem, což jsem doteď neměl).
Výsledek
Odečítání vodoměru mi běží už několik týdnů a zatím funguje spolehlivě. Dle mých zkušeností se zákaznický portál BVK a portál SUEZ nemění, takže nepředpokládám, že by se to mělo rozbíjet. Vodoměr odesílá údaje jednou denně. Nahlásí aktuální stav a taky vývoj spotřeby po šesti hodinách za minulý den. Problém je, že k odečtu sice dojde mezi třetí a čtvrtou hodinou v noci, ale stav v portálu SUEZ se aktualizuje později a v nepravidelný čas. Zpravidla to je do deváté ráno, ale někdy to bylo až odpoledne. Kvůli tomu spouštím scrapování dvakrát denně. Pokud se aktualizace zpozdí a nezachytí ji scrapování v devět ráno, je tu ještě scrapování v devět večer.
Během něj se spustí Chromium, prokliká se až na obrazovku se stavem vodoměru, ten se zapíše a uloží do souboru, který periodicky kontroluje služba, která hodnotu zprostředkuje přes REST API. Na straně HA je pak definovaný jednoduchý senzor, který hodnotu ze serveru odečítá jednou za hodinu.
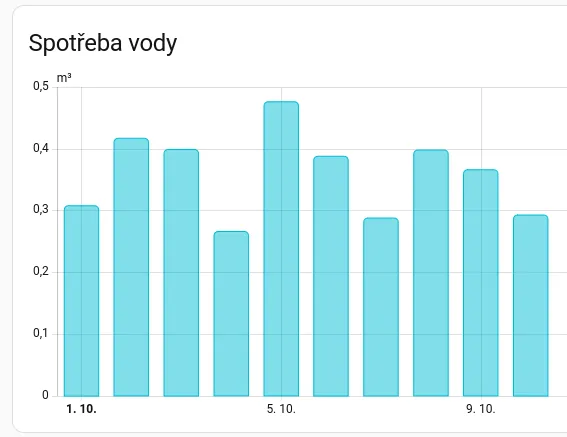
Pokud by se vám odečítání vodoměru SUEZ, dal jsem to jako projekt na Codeberg. Pokud jste u BVK, mělo by stačit jen nastavit přihlašovací údaje a číslo odběrného místa. Pokud máte chytrý vodoměr SUEZ u jiných vodáren, bude asi potřeba upravit cestu, jak se dostat na portál SUEZ, ale zbytek by měl opět fungovat.
Napsat komentář